![[미래교육 칼럼] 13. 인공지능 기술의 발전](https://koreanlifenews.com/wp-content/uploads/2018/12/C-3-2-768x365.jpg "[미래교육 칼럼] 13. 인공지능 기술의 발전")

4차 산업혁명에서 현재와 같은 수준의 자동화를 가능케 한 핵심기술은 인공지능이다. 따라서 이번 호에서는 인공지능 기술 발전의 역사와 기계학습(Machine Learning)에 대해 알아보기로 하자.
1. 인공지능의 역사
최초의 인공지능 프로그램
1950년~1951년에 Allen Newell, Herbert A. Simon 그리고 Cliff Shaw가 만든 컴퓨터 프로그램 Logic Theorist는 러셀과 화이트헤드가 쓴 『Principia Mathematica』2장에 나오는 52개의 수학 증명문제 중 38개를 풀었다. Logic Theorist는 수학 증명문제 외에 다른 문제들도 풀 수 있었다.
첫번째 인공지능 낙관의 시대(1950년~1974년)
얼마 후 IBM에서 일하던 Arthur Samuel이 체커스(checkers) 게임 프로그램을 만들었는데, 이것은 스스로 배우는 기계학습(Machine Learning) 능력을 가진 최초의 프로그램이었다. checkers 프로그램은 대국할 때마다 스스로 배워서 나중에는 그 프로그램의 창조자보다 더 잘하게 되었다.
이 초창기의 성공은 컴퓨터를 연구하던 많은 사람들을 흥분시켰고, 몇몇 학자들은 인간 수준의 인공지능이 몇 년 후면 가능할 것이라 믿었다. 그리고 1960년대 중반에 정신병자 치료용으로 개발되었던 최초의 문자기반 대화시스템(chatbot) ELIZA도 이런 기대감을 더했다.
하지만 이 인공지능 프로그램들은 비교적 단순한 문제풀이나 체커스 같은 게임에는 잘 동작했지만 복잡한 문제나 게임에는 큰 문제점을 노출시켰다. 5줄짜리 증명 문제는 풀 수 있지만 50줄짜리 증명 문제는 지금의 컴퓨터 성능으로도 불가능하기 때문이다. 그렇지만 인공지능의 개념 정립과 다양한 시도를 해본 의미 있는 시기라고 할 수 있다.
1차 인공지능 겨울
이런 문제점들은 많은 사람들의 실망을 가져왔고 1974년 전후로 인공지능에 대한 연구지원금이 끊기는 1차 인공지능 겨울이 도래했다. 이때까지의 인공지능 이론과 프로그램들은 GOFAI(Good Old Fashioned AI)라고 불린다.
두번째 인공지능 낙관의 시대(1980년~1980년대 후반)
1차 인공지능 겨울은 80년 전후로 상용을 목표로 시작된 전문가 시스템(expert system) 바람에 의해 녹았다. 전문가 시스템은 80년 후반까지 일본을 중심으로 뜨거운 관심을 받았지만 머지 않아 문제점을 드러냈다. 전문 지식을 프로그래머가 일일이 코딩해서 전문 지식이 필요한 사용자들에게 서비스할 계획이었지만 너무 복잡하고 변화에 대응하기 어려우며 오류 또한 너무 많아서 결국 접어야 했다. 희망을 갖고 많은 돈과 시간과 노력을 들였던 전문가 시스템들이 실패하면서 2차 인공지능 겨울이 찾아왔다.
2차 인공지능 겨울(1990년대초~2005년경)
2차 인공지능 겨울에도 실망에 따른 연구지원금 축소 현상이 일어났다. 두 번째 인공지능 겨울의 충격은 6~7년 만에 끝났지만 그 여파는 2005년까지 지속되었다. 이 비교적 긴 겨울 동안에도 인공지능 요소들의 발전은 계속되었다. 특히 1997에 IBM의 인공지능 Deep Blue가 세계 체스 챔피언 카스파로프(Kasparov)를 이기는 성과를 거두었다. 이때 인공지능은 기피 용어였기 때문에 이런 발전들이 발표될 때도 종종 인공지능이라고 명시하지 않았다.
세번째 인공지능 낙관 및 보편화의 시대(2005년경~현재)
현재 일고 있는 인공지능 붐은 인공지능 발전 초기의 여러 가지 이론과 실험에 뿌리를 두고 있고 인터넷과 급격하게 늘어난 데이터, 그리고 대폭적으로 향상된 컴퓨터 성능에 기인한다.
인공지능에 대한 근래의 폭발적인 관심과 투자의 변곡점은 2011년 전후라고 할 수 있다. 이 해에 구글은 Google Brain 프로젝트를 시작했고 IBM은 퀴즈쇼 Jeopardy!에 인공지능 시스템 WATSON을 출전시켜 우승했다.
1990년대 초반부터 시작된 인터넷 혁명과 일반용 컴퓨터 뿐만 아니라 휴대폰 같은 이동 컴퓨터의 폭발적 보급과 최근에는 여러가지 센서의 폭발적 성장으로 이러한 기기에서 얻어지는 데이터도 폭발적으로 늘어나 인공지능의 보편화의 조건이 성숙되었다.
기계학습(Machine Learning, ML)
현재의 인공지능에서 가장 큰 역할을 하고 있는 기계학습(Machine Learning, ML) 기술에 대해 알아보자. 여기서 기계라 함은 사실상 소프트웨어를 의미한다. 로봇도 하드웨어에 소프트웨어를 얹어야 주변을 인지하고 움직이는 것이 가능하다.
기계학습 능력을 갖춘 로봇이나 소프트웨어는 사람처럼 경험을 통해서 배운다. 체커스 프로그램으로 기계학습을 처음 시작한 Arthur Samuel은 기계학습을 컴퓨터가 일일이 프로그램되지 않아도 배울수 있는 능력으로 정의했다.
기계학습 능력이 없는 소프트웨어는 프로그래머가 일일이 써준대로만 동작한다. 예를 들어 기계학습 능력이 없는 장기 프로그램은 같은 수로 계속 져도 그 경험으로부터 배우지 못한다. 반면 기계학습으로 무장한 프로그램은 실패로부터 배워 같은 수를 다시 두지 않고 다른 수를 시도한다. 기계학습은 데이터에서 패턴인식을 해서 배운다.
우리가 늘 사용하는 구글 검색은 구글의 검색 엔진에 의해 검색 결과를 보여준다. 요즘엔 이 검색 엔진의 알고리즘이 RankBrain이라는 기계학습을 이용하면서 더 영리해졌다. 사용자가 입력한 단어들을 단순히 키워드의 나열로 사용했던 과거와 달리 기계학습을 통해서 사용자가 의미하는 것을 배운다. 또 검색결과를 사용자가 어떻게 사용하는지를 추적해서 다음 검색에 반영한다.
신경망 컴퓨터
1951년 Marvin Minsky와 Dean Edmunds는 최초의 신경망 SNARC(Stochastic Neural Analog Reinforcement Calculator)를 구축했다. 지금 기준으로 보면 아주 규모가 작은 3,000개의 진공관으로 단 40개의 뉴런의 신경망을 구성했다. 이 신경망은 쥐가 미로에서 먹이를 찾는 과정을 시뮬레이션했다. 컴퓨터에서의 신경망 구성은 충분한 데이터와 최소한의 컴퓨터의 성능이 확보될 때까지 큰 관심을 받지 못했다. 1986년에 여러 층(layer)으로 신경망을 구성한 딥러닝(Deep Learning)이 도입되었지만 위의 그래프에 있는 것처럼 2006년 전후의 변곡점이 지나서야 관심이 크게 확대되기 시작했다.
2. 학습 알고리즘의 종류
지도학습(Supervised Learning): 올바른 입력/출력 쌍으로 된 훈련데이터로부터 입출력간의 함수
지도학습은 학습 데이터에 입력값과 출력값이 있는데 스팸 메일 필터, 음성인식, 번역, 의료용 방사선 사진 판독 등의 훈련용 데이터가 그 예이다. 다른 말로 하면 각각의 데이터 항목에 표지(label)이 붙어 있다. 이 표지가 붙어 있는 대량의 데이터로 프로그램을 훈련시킨 다음 새로운 데이터 항목을 입력하면 훈련용 데이터로 배운대로 그 새로운 데이터 항목에 표지(label)을 출력한다.
예를 들어 구글이나 야후 등의 메일 서비스들은 기계학습을 이용한 스팸필터를 사용하기 때문에 정확도가 훨씬 높아졌다. 이 최신 스팸 메일 필터는 이미 확인된 수많은 스팸 메일과 정상 메일 데이터로 훈련시킨 프로그램이고 사용자가 스팸 메일 박스에서 꺼내서 읽는 메일, 정상 메일 박스에서 스팸처리하는 메일로 자동으로 재훈련한다. 이렇게 훈련된 프로그램은 새로운 메일이 도착하면 훈련된 대로 그 메일이 스팸 여부를 결정하여 해당 메일박스에 저장한다.
자율학습(Unsupervised Learning): 데이터의 무리짓기(Clustering) 또는 일관된 해석의 도출
자율학습 알고리즘에 사용되는 데이터에는 표지(label)가 붙어 있지 않다. 따라서 프로그램이 패턴을 인식해서 스스로 분류를 해야 한다. 2012년 구글이 아주 강력한 신경망 컴퓨터를 수많은 유튜브 데이터로 훈련시켰을 때 사람의 얼굴과 고양이의 얼굴을 구분해 냈다. 이 기계 학습의 중요한 이정표에서 자율학습 알고리즘이 사용됐다.
강화학습(Reinforcement Learning): 지도나 훈련용 데이터 없이도 실전에서 배울 수 있는 알고리즘
개에게 좀 복잡한 일을 가르칠 때 우리는 보통 상벌을 이용한다. 개가 일을 성공적으로 수행했을 때는 먹이를 주고 그렇지 않으면 혼내기를 반복하면 개가 점점 일을 잘 수행하게 된다. 이 아이디어를 차용해서 자동으로 상벌을 적용한 알고리즘이 강화학습이다. 2016년 이세돌을 이긴 알파고가 강화학습 알고리즘을 사용했다.
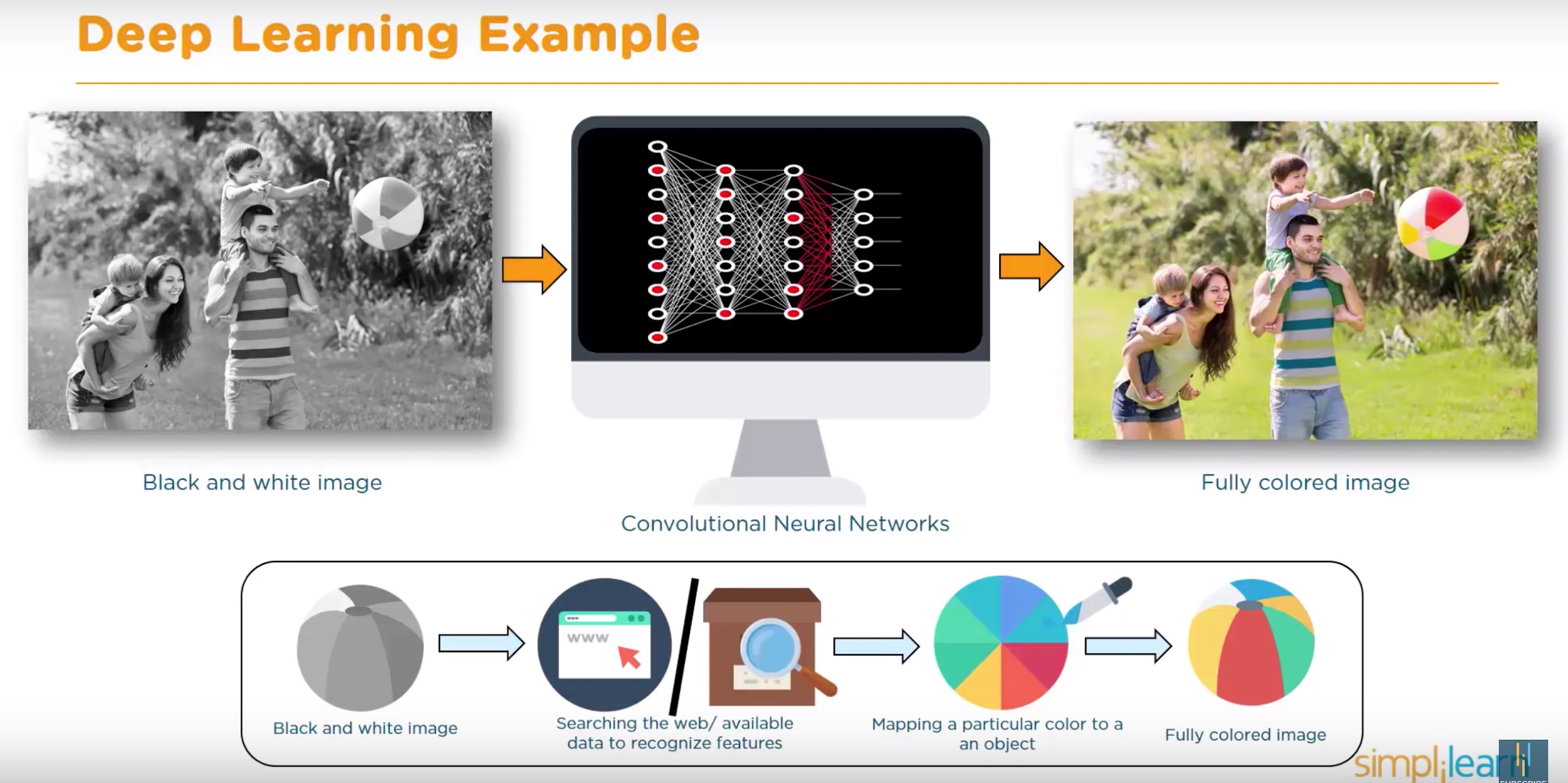
딥러닝(Deep Learning)
딥러닝은 신경망 컴퓨터를 여러층(layer)로 구성했을 때 그 층의 깊이에서 온 말이다. 층이 많아져 깊어 질수록 더 거시적이거나 추상적인 패던을 인식할 수 있다.
앞에서 잠깐 언급했던 것처럼 신경망 컴퓨터는 우리 뇌의 뉴런과 그 뉴런들을 잇는 시냅스를 아주 간단한 형태로 컴퓨터 프로그램으로 구현한 것이다.
우리가 학습과 훈련을 하면 특정 시냅스가 생성되고 굵어지는 것처럼 신경망 컴퓨터의 수많은 뉴런들도 훈련용 데이터에서 반복되는 특징들을 기억하게 된다.
위의 그림은 딥러닝을 사용하여 수많은 컬러 사진으로 훈련된 사진 변환 프로그램이 주어진 흑백 사진에 컬러를 입히는 과정을 보여준다. 흑백사진에서는 단지 회색으로 보여지는 비치볼의 세 부분을 다른 많은 비슷한 비치볼의 컬러 사진들을 참조해서 빨강, 연두, 노랑으로 색을 입혔다.
딥러닝은 주로 위에서 소개한 세가지 학습 알고리즘과 같이 사용되어 인공지능의 폭발적 발전과 보편화를 이끌고 있다.
다음 호에서는
지금 우리 삶을 바꿔놓고 있는 혁신적인 알파고 기술, 딥러닝은 70년 동안의 인공지능기술 진화의 산물이다.
하지만 인공지능이 많이 발달했어도 사람의 여러 가지 다양한 능력에 비하면 인공지능이 할 수 있는 일은 매우 제한적이다. 이 제한된 분야에서도 인공지능의 능력은 엄청난 경제적 가치를 갖고 있고 모든 주요 산업에 영향을 미치고 있으며 컴퓨터가 할 수 있는 영역은 점점 확대되고 있다.
이 인공지능 기술과 함께 사회, 경제, 그리고 정치 시스템까지도 바꿀 수 있는 파괴력을 갖고 있는 기술이 성장하고 있다.
얼마 전 세계를 떠들썩하게 했던 비트코인의 기반 기술인 블록체인(blockchain)이 바로 그것이다. 다음에는 4차 산업혁명에서 인공지능과 함께 중요한 역할을 할것으로 전망되는 이 블록체인 기술에 대해 알아본다.
칼럼에 대한 회신은 [email protected]으로 해 주시기 바랍니다.